
INSERT IGNORE is used in our organization to insert new records and ignore records that have the same primary key. This ignores the duplicate key exception that is generated and simply throws away the record. This allows for inserting those records to not make without having to employ a LEFT JOIN to avoid the duplication.
Researching further the IGNORE modifier on the INSERT statement in MySQL led me to the following information.
First paragraph of the documentation on MySQL IGNORE (https://dev.mysql.com/doc/refman/5.5/en/insert.html)
If you use the IGNORE modifier, errors that occur while executing the INSERT statement are ignored. For example, without IGNORE, a row that duplicates an existing UNIQUE index or PRIMARY KEY value in the table causes a duplicate-key error and the statement is aborted. With IGNORE, the row is discarded and no error occurs. Ignored errors may generate warnings instead, although duplicate-key errors do not.
This is the behavior that we primarily utilize the IGNORE modifier on INSERT statements.
It is not until the 3rd paragraph that the dangers of using the IGNORE modifier are apparent
Data conversions that would trigger errors abort the statement if IGNORE is not specified. With IGNORE, invalid values are adjusted to the closest values and inserted; warnings are produced but the statement does not abort. You can determine with the mysql_info() C API function how many rows were actually inserted into the table.
Just to be certain that everyone sees the danger in this statement it is contained in this sentence “With IGNORE, invalid values are adjusted to the closest values and inserted;” This causes the column’s null validation requirements to be forcefully bypassed by MySQL on INSERT when the IGNORE modifier is used!!
The following example demonstrates this effect
use test;
CREATE TEMPORARY TABLE RWH_TEST_INSERTS (
`id` INT PRIMARY KEY AUTO_INCREMENT,
`number` INT NOT NULL,
`number2` INT NOT NULL,
`date` DATE NOT NULL,
UNIQUE `nuux` (`number`)
);
INSERT INTO RWH_TEST_INSERTS (`number`,`number2`, date) VALUES (1,1, NOW());
SELECT * FROM RWH_TEST_INSERTS; #table 1
INSERT IGNORE INTO RWH_TEST_INSERTS (`number`,`number2`, date) VALUES (1,1,NOW()); #fails, duplicate key violation on the `number` column
SELECT * FROM RWH_TEST_INSERTS; #table 2
INSERT IGNORE INTO RWH_TEST_INSERTS
SET
`number` = 2,
`number2` = NULL,
`date` = NULL
; #succeeds!! There is no duplicate key violation so the nulls are forced to have value
SELECT * FROM RWH_TEST_INSERTS; #table 3
INSERT IGNORE INTO RWH_TEST_INSERTS
SET
`number` = 3,
`number2` = NULL,
`date` = NULL
; #succeeds!! There is no duplicate key violation so the nulls are forced to have value
SELECT * FROM RWH_TEST_INSERTS; #table 4
DROP TABLE IF EXISTS RWH_TEST_INSERTS;
Results of the SELECT * queries.

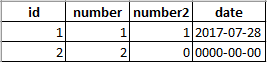
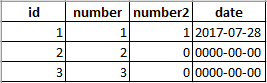
Therefore I highly recommend against the use of INSERT IGNORE in most circumstances. If you are using it to avoid failure on duplicate key exceptions there are other means that can be used to accomplish this same safeguard.